Architecture - Cross-Cloud Data Highways
Background
Imagine you need to move terabytes or petabytes of large files from AWS S3 to Azure Blob Storage, and that too with
- Reliability &
- High Throughput
The naïve approach (download the whole file, upload whole file) collapses under real‑world realities:
- Network glitches
- Process crashes
- Cloud throttling
- Feasibility of buffering a 1 TB of file in memory
What looks like a simple file-copy operation - is a classic distributed systems problem with:
- Partial failures
- Idempotency
- Data consistency across cloud
Recently I implemented it for one of my client and hence thought to unpack the foundational design principles that turned their existing fragile script into a production‑grade, resumable, and exactly‑once transfer pipeline.
Considering the magnitude and complexity of problem, this will be shared over a series of articles that will cover core architecture, chunk‑level strategies, cross‑cloud consistency, and why deterministic identifiers are key to this problem
High Level Architecture
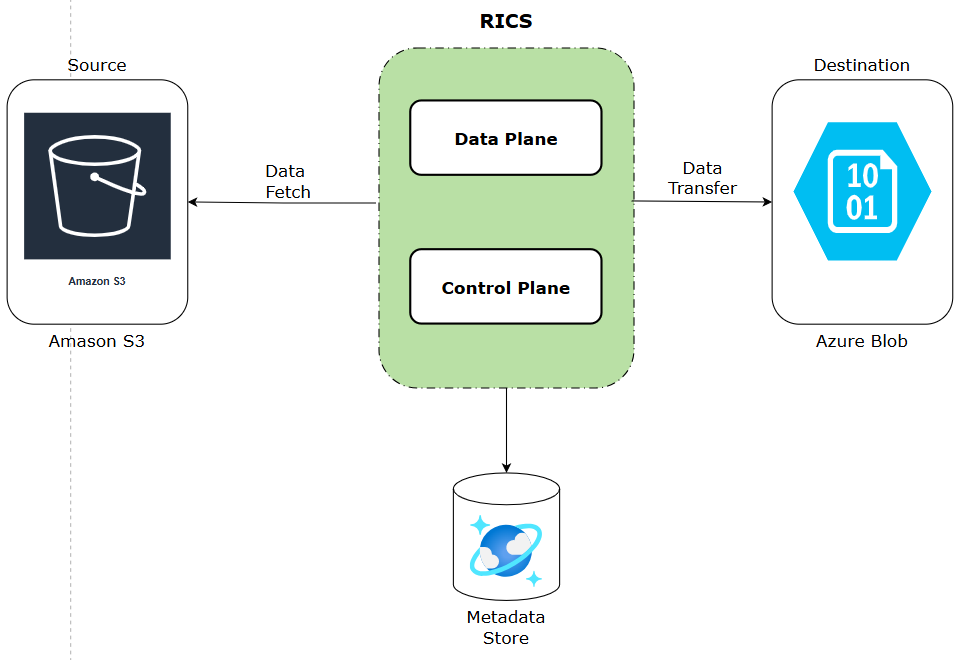
RICS (Resilient Inter Cloud Streaming) is structured as a streaming, pull-based transfer pipeline with a logical separation between the data plane and the control plane.
Data Plane
- Streams bytes directly from AWS S3 to Azure Blob Storage using ranged reads and block uploads
- No intermediate disk — data flows chunk by chunk through the JVM heap
- Stateless application that can be scaled horizontally
Control Plane
- Metadata store tracks every file and every chunk: PENDING → IN_PROGRESS → COMPLETED / FAILED
- Drives retry, resume, backpressure, and throttling decisions
- Acts as the single source of truth for transfer state
The key architectural insight: data plane is streaming; control plane is metadata-driven. These two concerns are mutually exclusive.
Core Design Principles
1. Chunked Transfers - Not a Single Stream
Files are split into fixed-size chunks (64–256 MB, tunable). Each chunk maps to:
- An S3 ranged GET (HTTP Range header)
- An Azure block upload (stageBlock API)
This creates the foundation for resumability, parallel upload, and bounded retry. The chunk-to-block mapping is deterministic, which is what makes the whole system idempotent.
2. Stateless Workers
Workers carry zero in-memory state between operations. All progress is externalized to the metadata store (Azure Cosmos DB, or any other persistent store) managed by Control Plane. Since state lives within meta-data store, RICS application is -
- Reliable : w.r.t data consistency and correctness
- Scalable : Throughput can be increased by adding more instances
3. Eventual Consistency with Correctness Guarantees
RICS doesn't chase strong cross-cloud consistency. Instead it guarantees:
- A file is visible to consumers only after atomic blob commit
- Partial uploads are never exposed
- Retries converge to the same correct final state
RICS trade immediate consistency for throughput, but never expose corrupt data
Technology Stack
- JDK 21
- Spring Boot 3.x
- Spring Core Reactor
- AWS SDK
- Azure Blob SDK
Key Trade-offs
- No real-time replication — this is batch-oriented, high data volume movement
- Double egress cost (AWS out + Azure in) — justified by reliability and control
- Eventual consistency across clouds — acceptable when commit is atomic
Conclusion
In this article we took a stab at what problem RICS intends to solve along with its high level architecture, design principles and architectural trade-offs.
Architecture tells you what the system looks like. Performance tells you how fast it actually moves. In Part 2, we will go under the hood of the two mechanisms that determine throughput: S3 ranged reads and Azure block blob uploads - So stay Tuned!
comments powered by Disqus