Resilient & Fault Tolerant - Cross-Cloud Data Highways
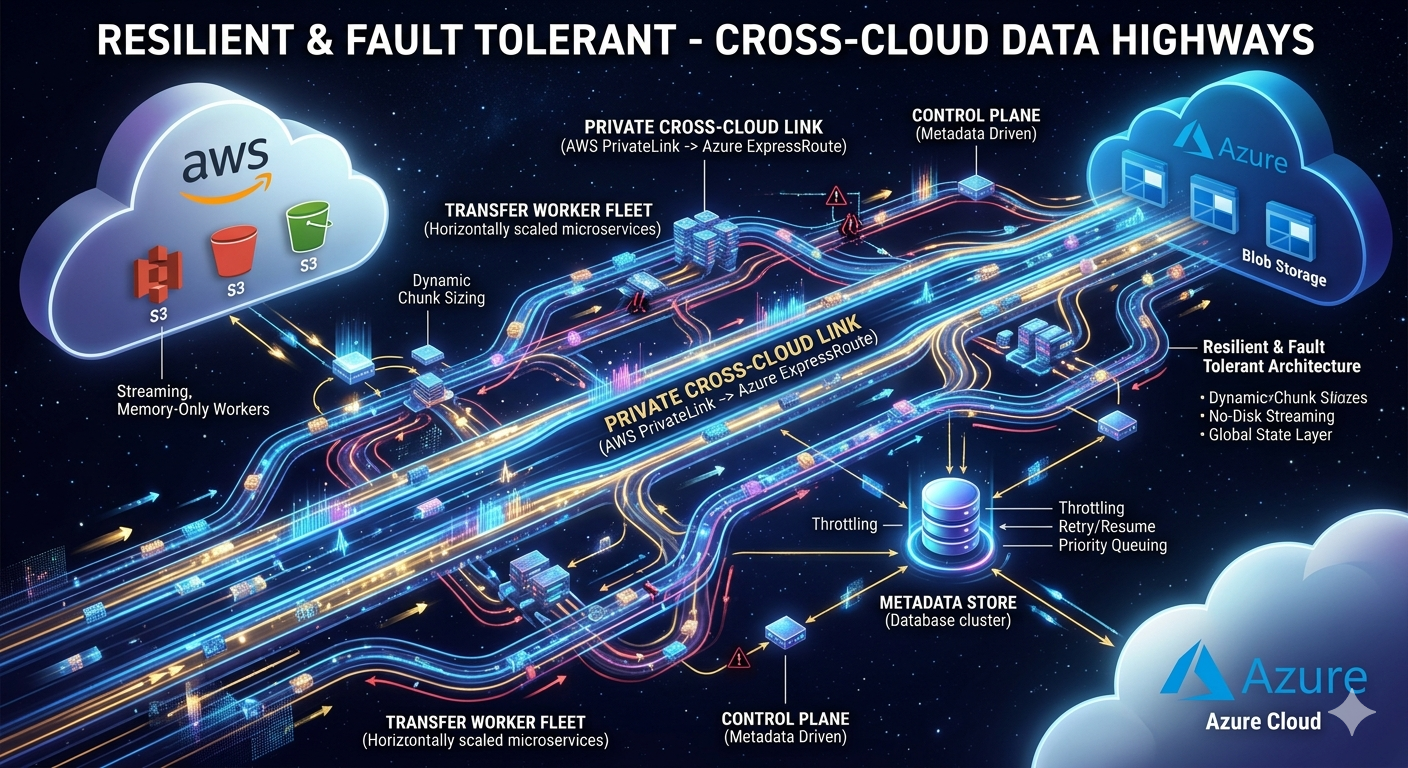
Background
Parts 1 and 2 established the what and the how fast — a stateless, chunk-driven pipeline with deterministic block IDs, reactive backpressure, and an adaptive concurrency controller functions under real cloud conditions. But speed and elegant architecture count for nothing if application crash at chunk 73 of 120, or if a transient Azure 503 silently corrupts a partially assembled blob. Part 3 is about the third dimension: how well does RICS survive when things go wrong?
The Core Philosophy - Design for Failure First
In RICS, failures are not exceptional. They are expected. The system is designed so that failures are safe, retries are harmless, and final state always converges to correctness.
Failure Taxonomy — What Can Actually Go Wrong
Transient Failures
- Network hiccups between S3 and JVM or JVM and Azure
- AWS S3 throttling (HTTP 503, SlowDown)
- Azure transient errors (HTTP 429, 500, 503)
- DNS resolution timeouts
Infrastructure Failures
- VM restart mid-transfer
- VM crashes under memory pressure
- Cloud region partial outage
Logical Failures
- Metadata write succeeds but data upload fails (state mismatch)
- Data upload succeeds but metadata update fails
- Duplicate triggers for the same file
- Concurrent applications processing the same chunk
Idempotency
RICS achieves system-wide idempotency through three interlocking mechanisms:
1. Deterministic File Identity
Every transfer job is derived from a deterministic fingerprint:
1 FileId = hash(sourceBucket + sourceKey + versionId + fileSize)
Duplicate triggers map to the same metadata entry. So No duplicate work begins.
2. Deterministic Block IDs
1 blockId = Base64.encode(String.format("%06d", chunkIndex))
Re-uploading the same chunk overwrites the same Azure block. No data duplication. Hence safe to retry any number of times.
3. Atomic Blob Commit
The blob only becomes visible after commitBlockList() succeeds. Until then, no consumer sees partial data. The commit call itself is idempotent — retrying it with the same block list is safe.
Chunk as the atomic unit
The chunk boundary is the key design decision that makes everything else tractable. Each chunk is:
- Independently retryable — failure scope is bounded to chunk size, not file size
- Independently verifiable — checksum can be validated per chunk
- Independently resumable — restart from the last incomplete chunk index
Resumability - Surviving VM Crashes
RICS stores chunk-level progress in an external metadata store. Every chunk transitions through:
PENDING → IN_PROGRESS → COMPLETED
Example - Crash at chunk 37 of 120? On restart:
- Query metadata store — see chunks 0–36 COMPLETED
- Filter incomplete chunks — start from chunk 37
- Re-upload chunk 37 — deterministic block ID overwrites any partial upload safely
- Continue to chunk 120 — commit block list
No manual intervention. No data loss. No corruption.
A VM can crash mid-transfer and another VM can resume without data loss
Failure Scenario Playbook
Scenario-1: Chunk uploaded to Azure, metadata update failed
Result: Chunk will be retried. Same block ID overwrites the previous upload. No duplication. Metadata lags behind reality but correctness is preserved.
Scenario-2: App crashes after all chunks uploaded but before commit
Result: On restart, metadata shows all chunks COMPLETED but blob status is not COMMITTED. System re-attempts commitBlockList. Commit is idempotent by design.
Scenario-3: S3 object changes during transfer
Result: RICS locks to a specific versionId before starting. If the source changes mid-transfer, the transfer is rejected or flagged for restart.
Retry Strategy
Key design choices made from very beginning:
- Retry is per chunk and not per file
- Backoff is exponential (with jitters)
- Non transient errors are not retried
1 Retry
2 .backoff(props.transfer().maxChunkRetries(), Duration.ofMillis(props.resilience().initialBackoffMs()))
3 .maxBackoff(Duration.ofMillis(props.resilience().maxBackoffMs()))
4 .jitter(props.resilience().jitterFactor())
5 .filter(this::isTransientError)
Dead-Letter State for Poisoned Files
Files that exhaust retries transition to DEAD_LETTER state. This prevents indefinite retry storms and enables targeted manual investigation.
Conclusion
Resiliency in RICS is not an after thought - its a characteristic that is built around 3 key design decisions:
- Deterministic identifiers that make duplicate work safe
- External state management
- Chunk size as the unit of failure As a result cost of failure is bounded to chunk and not entire file. Part-4 will cover Observability and Monitoring aspect of RICS.